Voice cloning in 2026 is no longer experimental.
It’s production-ready.
It’s being deployed at scale.
And it’s powering everything from AI assistants to dubbing platforms.
It’s being deployed at scale.
And it’s powering everything from AI assistants to dubbing platforms.
But developers still debate one thing:
👉 Zero-shot or few-shot voice cloning - which is better?
Let’s break it down clearly.
First, What’s the Real Difference?
At a high level:
🚀 Zero-shot cloning → Clone a voice from just a few seconds of audio. No retraining.
🎙️ Few-shot cloning → Use several minutes of voice data and adapt the model for higher fidelity.
Both can sound realistic.
But they behave very differently in production.
But they behave very differently in production.
🚀 Zero-Shot Voice Cloning
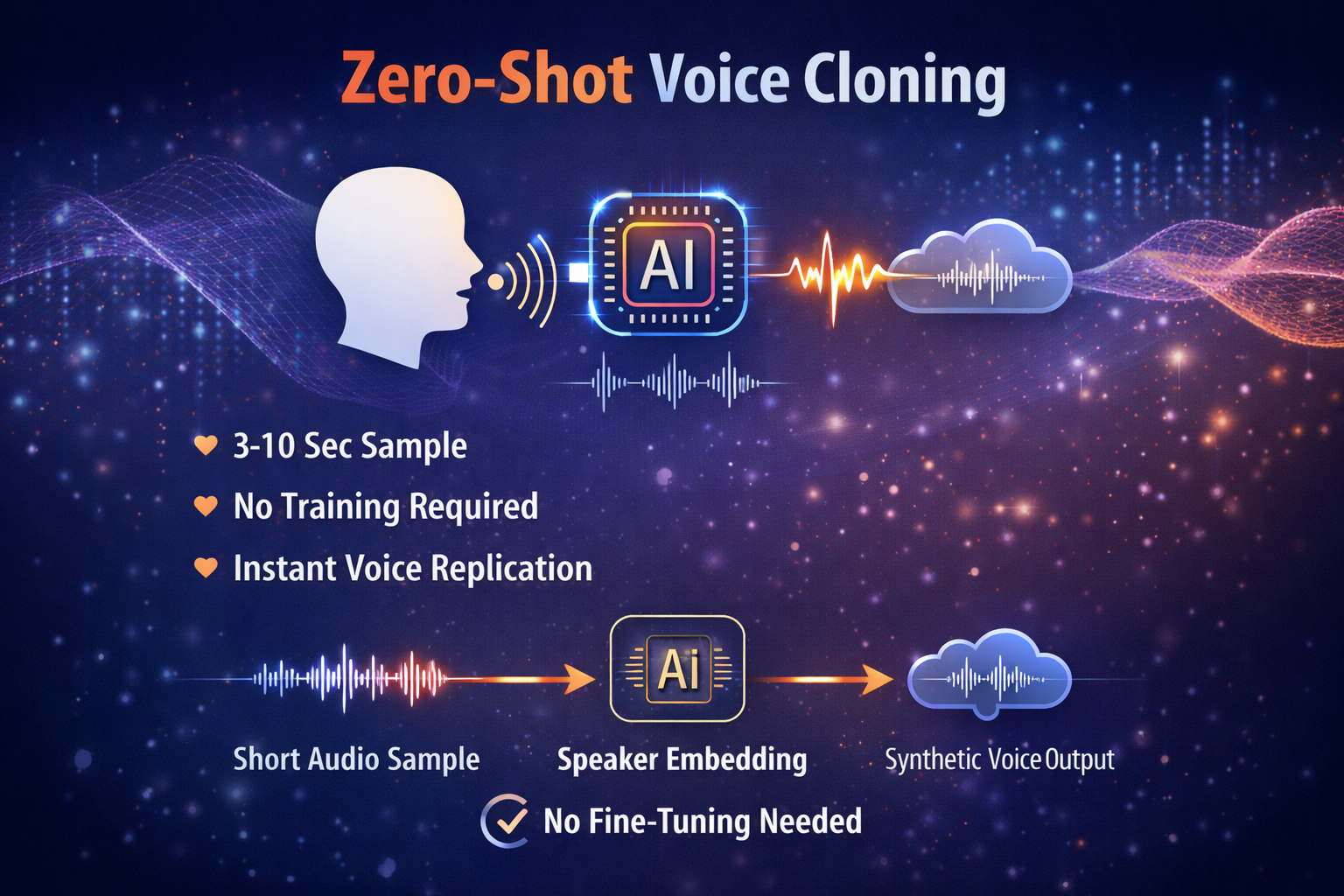
Zero-shot cloning works like this:
- You provide 3–10 seconds of clean audio
- The model extracts a speaker embedding
- It conditions speech generation on that embedding
No fine-tuning.
No retraining cycle.
Instant results.
No retraining cycle.
Instant results.
Why zero-shot dominates SaaS products
- ⚡ Instant onboarding
- 📈 Infinite scalability
- 💰 Lower infrastructure cost
- 🔄 Easier deployment
If you’re building:
- AI voice assistants
- User-personalized narration
- Multilingual chatbots
Zero-shot is incredibly practical.
But here’s the trade-off 👇
- Emotional nuance can be slightly weaker
- Long-form speech may drift subtly
- Quality depends heavily on reference audio
In 2024, the gap between zero-shot and few-shot was noticeable.
In 2026?
The gap is much smaller.
The gap is much smaller.
🎙️ Few-Shot Voice Cloning
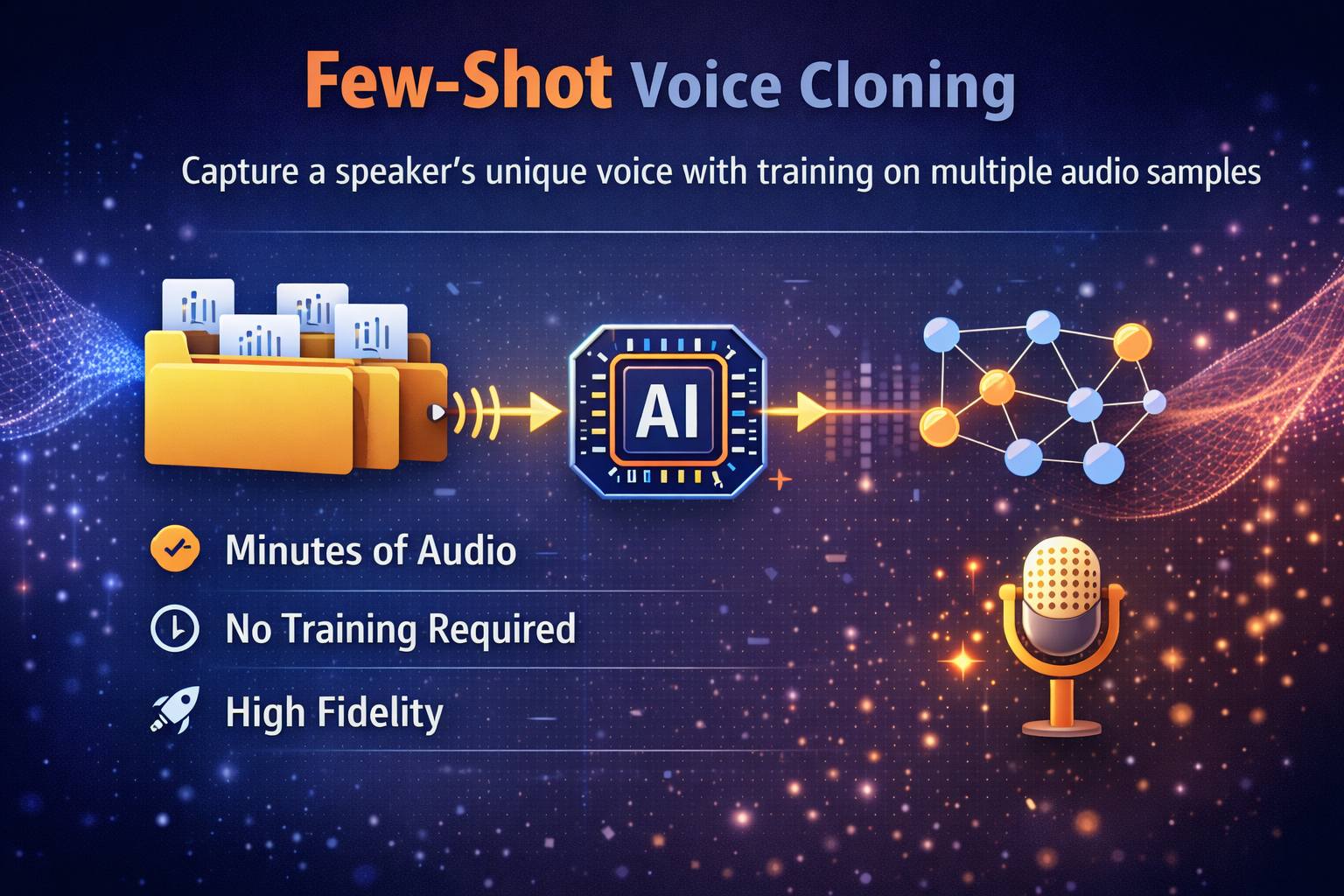
Few-shot cloning requires multiple high-quality recordings - usually several minutes.
Instead of just extracting an embedding, the model adapts or fine-tunes toward that speaker.
This produces:
- 🎵 Better micro-prosody
- 🎭 Stronger emotional depth
- 🎚️ More stable accent consistency
- 🧠 Tighter identity preservation
If you're producing:
- Audiobooks
- Voice branding
- High-end dubbing
- Premium voice licensing
Few-shot still wins in authenticity.
But few-shot has costs
- ⏳ Preparation time
- 💾 Storage requirements
- 🧠 More complex infrastructure
- ⚙️ Fine-tuning management
It’s not as plug-and-play.
Side-by-Side Comparison
| Feature | Zero-Shot 🚀 | Few-Shot 🎙️ |
| Data Required | 3–10 sec | Several minutes |
| Retraining Needed | ❌ No | ✅ Yes |
| Scalability | High | Limited |
| Authenticity | High | Very High |
| Production Ease | Simple | Complex |
What Changed in 2026?
Three big things:
🧠 Larger pretrained speech models
🌍 Massive multilingual training datasets
🎚️ Improved prosody modeling
🌍 Massive multilingual training datasets
🎚️ Improved prosody modeling
Modern zero-shot systems now reach over 90% speaker similarity in controlled environments.
That’s why many commercial platforms rely on zero-shot pipelines.
So… Which One Should You Choose?
It depends on your goal.
Choose 🚀 Zero-shot if:
- You need scale
- You onboard many users
- You prioritize speed and simplicity
Choose 🎙️ Few-shot if:
- You need premium realism
- Voice branding matters
- Emotional depth is critical
The most advanced systems in 2026 are actually hybrid - combining zero-shot scalability with lightweight adaptation.
Final Thought
- Zero-shot is winning the market.
- Few-shot is winning the studio.
The smartest choice isn’t about which sounds “better.”
It’s about what your product actually needs.
It’s about what your product actually needs.